Data Acquisition & Control

The CMB-S4 data acquisition and control (‘DAQ’) software will need to control and acquire data from the 550,000 high-speed detectors, as well as a myriad of systems on each of the 21 telescope platforms and across the site (the telescope platforms themselves, as well as the 100mK cryogenics, pumps, cooling loops, warm thermometry, calibrators, weather data, instrument settings, and many more). DAQ will also be developing the live monitoring system to assess system performance in real time.
This is a significant increase in system complexity and data rate compared to current generation experiments, and also must be deployed in advance in the laboratories with the detector, readout, and module testing equipment. The distributed, open-source, and user-friendly DAQ system for CMB-S4 is designed to handle the increased number of sub-systems, lab testing, and high-speed detector data.
Data Management
To achieve the sensitivity needed to meet its science goals, CMB-S4 is must gather an order of magnitude more data than any previous CMB experiment. Managing this volume will require scaling up our data transfer, storage, reduction, and distribution capabilities accordingly.
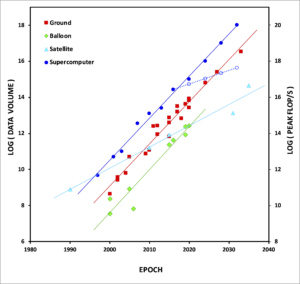
This data volume is exactly in line with the longstanding exponential growth in suborbital CMB data volumes, which perfectly parallels Moore’s Law in computing. This graph shows the growth in the volumes of data gathered by ground-based (red), balloon-borne (green), and satellite (cyan) CMB experiments over a 40-year period, and in computing power (blue – solid being Moore’s Law and dashed being projected actual performance) over the same period, using the peak performance of the NERSC flagship supercomputer at an epoch as a proxy. CMB-S4 is represented by the red point in the top right corner. Note that while Moore’s Law is ending, CMB data growth is not. Meeting our computational needs for the next 15+ years on increasingly constrained computing systems represents one of the major challenges for the data management subsystem.
To address this challenge we plan to assemble a suite of world-class national and international computing resources into an overall “superfacility” infrastructure. This will combine networking, in conjunction with the Energy Sciences Network (ESnet) and partners, high-performance computing, in conjunction with the National Energy Research Scientific Computing Center (NERSC) and the Argonne Leadership Computing Facility (ALCF), high-throughput computing, in conjunction with the Open Science Grid (OSG) and Extreme Science and Engineering Discovery Environment (XSEDE), and in-network computing, in conjunction with the FABRIC project.
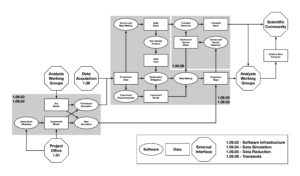
Detecting the tiny signals hidden in this dataset with high confidence requires exquisite control of systematic effects. This is achieved firstly by minimizing their occurrence through the optimization of the design of the instrument and its observing strategy, and secondly by minimizing their impact by mitigating them in the reduction and analysis of the data. In conjunction with the technical and analysis working groups, the data management subsystem also plays a key role in both of these efforts, providing simulations to inform specific trade studies and to validate the overall experiment design, and developing, deploying, and verifying mitigation strategies in the data reduction pipeline.
The diagram shows the planned flow of data (rectangles) through the various pipelines of software modules (ovals) to generate maps and event alerts for analysis, together with the interfaces to the other project subsystems, the collaboration working groups, and the scientific community at large. Shaded boxes represent the areas of responsibility of the various data management subgroups. This work builds on the expertise developed over many decades of CMB data management across all of the experiments that have come together to field the CMB-S4 experiment.